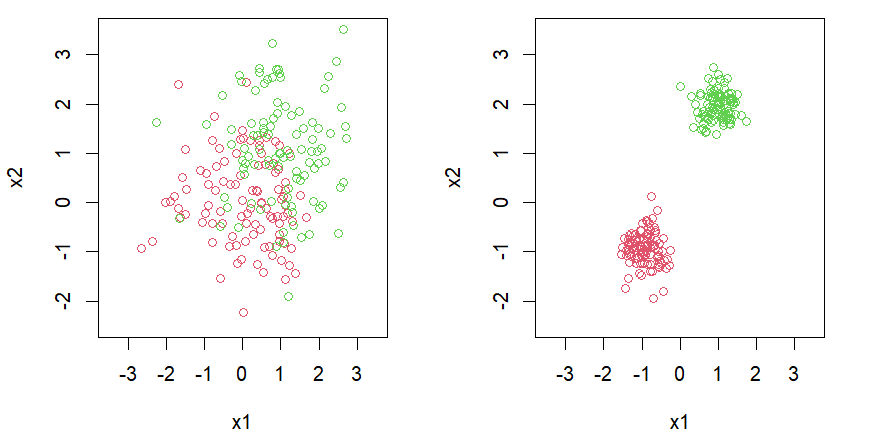
Linear Separable
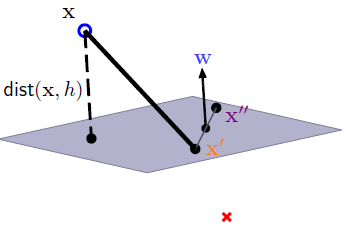
Distance
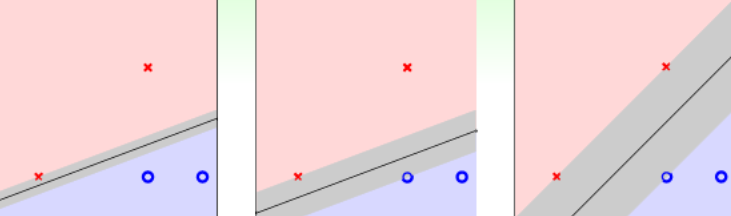
SVM
Hyperplane $\underset{\sim}{w}^T \underset{\sim}{x} + b$ and data point $\underset{\sim}{x_i}$ with label $y_i$
$$\begin{align*} \underset{b,\underset{\sim}{w}}{\text{arg max}} & \left( \text{margin}(\underset{\sim}{w},b) \right) \text{ subject to } \forall i,\ y_i ( \underset{\sim}{w}^T \underset{\sim}{x_i} + b) > 0 \end{align*}$$$$\begin{align*} \text{margin}(\underset{\sim}{w},b) = \min_i \text{dist}(\underset{\sim}{x_i},\underset{\sim}{w},b) = \min_i \frac{1}{\left| \underset{\sim}{w} \right|} \left| \underset{\sim}{w}^T \underset{\sim}{x_i} + b \right| \end{align*}$$$$\begin{align*} \underset{b,\underset{\sim}{\textcolor{orange}{w}}}{\text{arg max}} & \left( \frac{1}{\left| \underset{\sim}{\textcolor{orange}{w}} \right|} \min_i y_i (\underset{\sim}{{\textcolor{orange}{w}}^T} \underset{\sim}{x_i} + \textcolor{orange}{b}) \right) \\\\\\ & \text{subject to } \forall i,\ y_i ( \underset{\sim}{{\textcolor{orange}{w}}^T} \underset{\sim}{x_i} + \textcolor{orange}{b}) > 0 \end{align*}$$Let $\displaystyle \min_i y_i(\underset{\sim}{\textcolor{orange}{w}}^T \underset{\sim}{x_i} + \textcolor{orange}{b})=k$, then \quad $\displaystyle \min_i y_i({\underset{\sim}{\textcolor{orange}{w}}^T \frac{1}{k}} \underset{\sim}{x_i} + {\frac{\textcolor{orange}{b}}{k}} )=1$
Denote ${\underset{\sim}{\textcolor{orange}{w}}^T \frac{1}{k}}$ as $\textcolor{red}{\underset{\sim}{w}^T}$, $\frac{\textcolor{orange}{b}}{k}$ as $\textcolor{blue}{b}$
$$\begin{align*} \Leftrightarrow \ \underset{b,\underset{\sim}{w}}{\text{arg max}} \left( \frac{1}{\left| \underset{\sim}{w} \right|} \right) \quad \text{subject to } \min_i y_i (\underset{\sim}{w}^T \underset{\sim}{x_i} + b) = 1 \end{align*}$$$$\begin{align*} & \underset{b,\underset{\sim}{w}}{\text{arg max}} \left( \frac{1}{\left| \underset{\sim}{w} \right|} \right) \text{subject to } \min_i y_i (\underset{\sim}{w}^T \underset{\sim}{x_i} + b) = 1 \\\\\\ \end{align*}$$If optimal $(\textcolor{orange}{b},\underset{\sim}{\textcolor{orange}{w}})$ with $\min_i y_i (\underset{\sim}{\textcolor{orange}{w}}^T \underset{\sim}{x_i} + \textcolor{orange}{b}) = k>1$, we can scale $(\textcolor{orange}{b},\underset{\sim}{\textcolor{orange}{w}})$ to $({\frac{\textcolor{orange}{b}}{k}} ,{\frac{\underset{\sim}{\textcolor{orange}{w}}}{k}} )$
$$\begin{align*} \Leftrightarrow \ & \underset{b,\underset{\sim}{w}}{\text{arg max}} \left( \frac{1}{\left| \underset{\sim}{w} \right|} \right) \text{subject to } \forall i, \; y_i (\underset{\sim}{w}^T \underset{\sim}{x_i} + b) \geq 1 \end{align*}$$$$\begin{align*} & \underset{b,\underset{\sim}{w}}{\text{arg max}} \left( \frac{1}{\left| \underset{\sim}{w} \right|} \right) \quad \text{subject to } \forall i, \; y_i (\underset{\sim}{w}^T \underset{\sim}{x_i} + b) \geq 1 \\\\\\ \Leftrightarrow \ &\underset{b,\underset{\sim}{w}}{\text{arg min}} \left( \frac{1}{2} \underset{\sim}{w}^T \underset{\sim}{w} \right) \quad \text{subject to } \forall i, \; 1-y_i (\underset{\sim}{w}^T \underset{\sim}{x_i} + b) \leq 0 \end{align*}$$Let $\displaystyle L=\frac{1}{2} \underset{\sim}{w}^{T} \underset{\sim}{w} + \sum_{i=1}^{N} \lambda_{i}\left(1-y_{i}\left(\underset{\sim}{w}^{T} \underset{\sim}{x_i} +b\right)\right)$, and we claim that
$$\begin{align*} & \underset{b,\underset{\sim}{w}}{\text{arg min}} \left( \frac{1}{2} \underset{\sim}{w}^T \underset{\sim}{w} \right) \quad \text{subject to } \forall i, \; 1-y_i (\underset{\sim}{w}^T \underset{\sim}{x_i} + b) \leq 0 \\\\\\ \Leftrightarrow \ & \displaystyle \underset{b, \underset{\sim}{w}}{\text{arg min}} (\ \max _{\forall \lambda_{i} \geq 0} L\left(b, \underset{\sim}{w}, \lambda_{i}\right)) \end{align*}$$$$\begin{align*} & \underset{b,\underset{\sim}{w}}{\text{arg min}} \left( \frac{1}{2} \underset{\sim}{w}^T \underset{\sim}{w} \right) \quad \text{subject to } \forall i, \; 1-y_i (\underset{\sim}{w}^T \underset{\sim}{x_i} + b) \leq 0 \\\\\\ \Leftrightarrow \ & \displaystyle \underset{b, \underset{\sim}{w}}{\text{arg min}} (\ \max _{\forall \lambda_{i} \geq 0} L\left(b, \underset{\sim}{w}, \lambda_{i}\right)) \end{align*}$$Violating $(b, \underset{\sim}{w})$: \\\
\qquad \qquad $\displaystyle \max _{\forall \lambda_{i} \geq 0} L\left(b, \underset{\sim}{w}, \lambda_{i}\right) = \max _{\forall \lambda_{i} \geq 0} \frac{1}{2} \underset{\sim}{w}^{T} \underset{\sim}{w} + \sum_{i=1}^{N} \lambda_{i} (\textcolor{blue}{\text{positive}})$
Feasible $(b, \underset{\sim}{w})$: \\\
\qquad \qquad $\displaystyle \max _{\forall \lambda_{i} \geq 0} L\left(b, \underset{\sim}{w}, \lambda_{i}\right) = \max _{\forall \lambda_{i} \geq 0} \frac{1}{2} \underset{\sim}{w}^{T} \underset{\sim}{w} + \sum_{i=1}^{N} \lambda_{i} (\textcolor{blue}{\text{non-positive}})$
$$\begin{align*} &\max _{\forall \lambda_{i} \geq 0} L\left(b, \underset{\sim}{w}, \lambda_{i}\right) \geq L\left(b, \underset{\sim}{w}, \lambda_{i}^{*} \right), \quad \text{for some } \lambda_{i}^{*} \\\\\\ \Rightarrow \ & \min _{b, \underset{\sim}{w}}\left(\max _{\forall \lambda_{i} \geq 0} L\left(b, \underset{\sim}{w}, \lambda_{i}\right)\right) \geq \min _{b, \underset{\sim}{w}} L\left(b, \underset{\sim}{w}, \lambda_{i}^{*} \right), \quad \text{for some }\lambda_{i}^{*} \\\\\\ \Rightarrow \ & \min _{b, \underset{\sim}{w} }\left(\max _{\forall \lambda_{i} \geq 0} L\left(b, w, \lambda_{i}\right)\right) \geq \max _{\forall \lambda_{i} \geq 0} \left(\min _{b, \underset{\sim}{w}} L\left(b, \underset{\sim}{w}, \lambda_{i}\right) \right) \end{align*}$$Slater’s Condition
$$ \underset{b, \underset{\sim}{w}}{\text{arg min}} \frac{1}{2} \underset{\sim}{w}^T \underset{\sim}{w} \quad \text{subject to } 1-y_{i}\left(\underset{\sim}{w}^{T} \underset{\sim}{x_i} +b\right) \leq 0,\ i = 1, \ldots, N$$$$\begin{align*} \min _{b, \underset{\sim}{w}}\left(\max _{\forall \lambda_{i} \geq 0} L\left(b, \underset{\sim}{w}, \lambda_{i}\right)\right) = \max _{\forall \lambda_{i} \geq 0} \left(\min _{b, \underset{\sim}{w}} L\left(b, \underset{\sim}{w}, \lambda_{i}\right) \right) \end{align*}$$What’s more, the $b, \underset{\sim}{w}$ are the same
KKT Conditions
For convex optimization problem \\\ \qquad $\displaystyle \underset{b, \underset{\sim}{w}}{\text{arg min}} {\frac{1}{2} \underset{\sim}{w}^T \underset{\sim}{w} } \quad \text{subject to } {1-y_{i}\left(\underset{\sim}{w}^{T} \underset{\sim}{x_i} +b\right) } \leq 0,\\\\\\ i = 1, \ldots, N$
Denote $\frac{1}{2} \underset{\sim}{w}^T \underset{\sim}{w} $ as $\textcolor{red}{ f_0 }$, $1-y_{i}\left(\underset{\sim}{w}^{T} \underset{\sim}{x_i} +b\right)$ as $\textcolor{red}{f_1, \ldots, f_N}$ . Assume the functions $\textcolor{blue}{f_0,f_1, \ldots, f_N}$ are differentiable. The KKT conditions are \begin{enumerate} \item $\textcolor{blue}{f_i} \leq 0,\ i = 1, \ldots, N$ \item $\lambda_i \geq 0,\ i = 1, \ldots, N $ \item $\lambda_i \textcolor{blue}{f_i} = 0,\ i = 1, \ldots, N $ \item $\displaystyle \nabla \textcolor{blue}{f_0} + \sum_{i=1}^N \lambda_i \nabla \textcolor{blue}{f_i} = 0$ \end{enumerate}
$$\begin{align*} (b, \underset{\sim}{w}) \text{ is optimal } \Leftrightarrow (b, \underset{\sim}{w}) \text{ satisfies KKT conditions } \end{align*}$$$$\begin{align*} & \frac{\partial L}{\partial b}= -\sum_{i=1}^{N} \lambda_{i} y_{i}=0, \quad \frac{\partial L}{\partial w_{k}} = w_{k}-\sum_{i=1}^{N} \lambda_{i} y_{i} x_{i,k}=0 \\\\\\ & \text{where } \underset{\sim}{x_i} = (x_{i,1},\ \ldots ,\ x_{i,n}) \end{align*}$$\qquad \quad $\frac{\partial L}{\partial b}= -\sum_{i=1}^{N} \lambda_{i} y_{i}=0, \quad \frac{\partial L}{\partial w_{k}} = w_{k}-\sum_{i=1}^{N} \lambda_{i} y_{i} x_{i,k}=0 $
$$\begin{align*} & \underset{\forall \lambda_{i}{\text{arg max}} \geq 0} \left(\min _{b, \underset{\sim}{w}} L\left(b, \underset{\sim}{w}, \lambda_{i}\right)\right) \\\\\\ = & \underset{\forall \lambda_{i} \geq 0}{\text{arg max}} \left(\min _{b, \underset{\sim}{w}}\left(\frac{1}{2} \underset{\sim}{w}^{T} \underset{\sim}{w}+\sum_{i=1}^{N} \lambda_{i}\left(1-y_{i}\left(\underset{\sim}{w}^{T} \underset{\sim}{x_i}+b\right)\right)\right)\right) \\\\\\ = & \underset{\forall \lambda_{i} \geq 0}{\text{arg max} } \left(\min _{b, \underset{\sim}{w}} \left(\frac{1}{2} \underset{\sim}{w}^{T} \underset{\sim}{w}+\sum_{i=1}^{N} \lambda_{i}-\underset{\sim}{w}^{T} \underset{\sim}{w}+0\right)\right) \\\\\\ = & \underset{\forall \lambda_{i} \geq 0}{\text{arg max}} \left(-\frac{1}{2}\left|\sum_{i=1}^{N} \lambda_{i} y_{i} \underset{\sim}{x_i} \right|^{2}+\sum_{i=1}^{N} \lambda_{i}\right) \end{align*}$$Quadratic Programming
$$\begin{align*} \underset{\forall \lambda_{i} \geq 0}{\text{arg min}} & \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_i \lambda_j y_i y_j \underset{\sim}{x_i}^T \underset{\sim}{x_j} - \sum_{i=1}^{N} \lambda_i \\\\\\ & \text{subject to } \sum_{i=1}^{N} y_i \lambda_i = 0 \text{ and } \forall i, \lambda_i \geq 0 \\\\\\ \end{align*}$$Rewrite as \ $\underset{\forall \lambda_{i} \geq 0}{\text{arg min}} \frac{1}{2} \underset{\sim}{\lambda}^T Q \underset{\sim}{\lambda} + p^T \underset{\sim}{\lambda} \quad \text{ subject to } \underset{\sim}{y^T} \underset{\sim}{\lambda} \geq 0$, $\underset{\sim}{y} \underset{\sim}{\lambda} \leq 0$
$$\begin{align*} Q=\begin{bmatrix} y_1 y_1 \underset{\sim}{x_1}^T \underset{\sim}{x_1} & \cdots & y_1 y_{\scriptscriptstyle N} \underset{\sim}{x_1}^T \underset{\sim}{x_{\scriptscriptstyle N} } \\\\\\ \vdots & \ddots & \vdots \\\\\\ y_{\scriptscriptstyle N} y_1 \underset{\sim}{x_{\scriptscriptstyle N} }^T \underset{\sim}{x_1} & \cdots & y_{\scriptscriptstyle N} y_{\scriptscriptstyle N} \underset{\sim}{x_{\scriptscriptstyle N} }^T \underset{\sim}{x_{\scriptscriptstyle N} } \end{bmatrix} \end{align*}$$Example
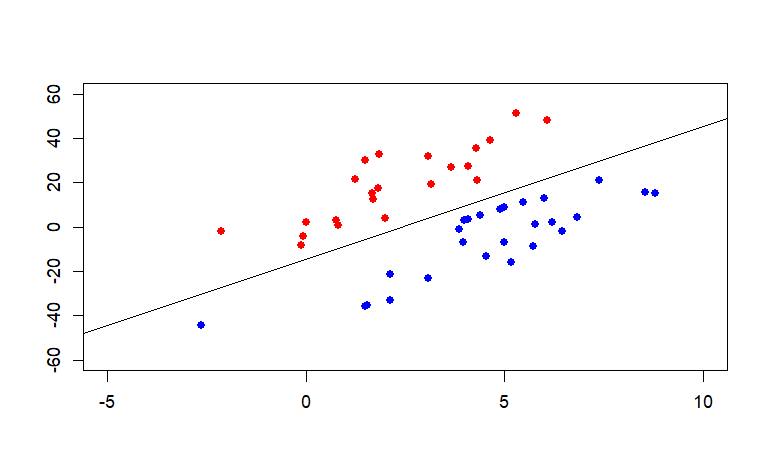
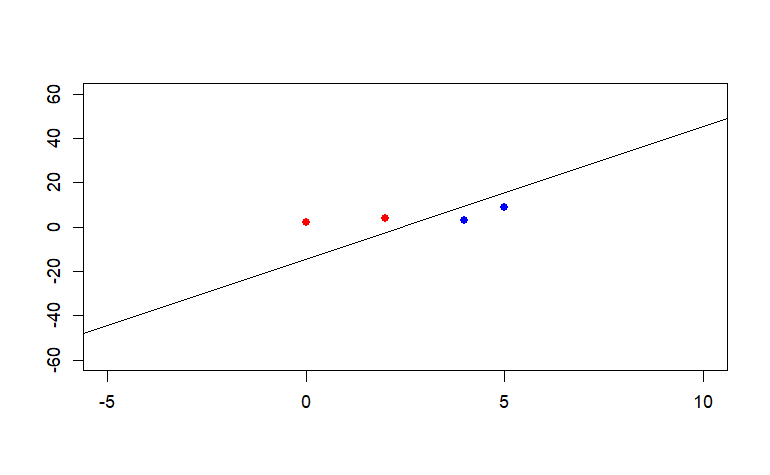
Check the outcome of svm and QP are equal.
4 data points
| |
48 data points
| |
Reference
Convex Optimization
Method of Lagrange Multipliers
線代啟示錄
Karush-Kuhn-Tucker conditions pdf
Karush-Kuhn-Tucker conditions
林軒田-機器學習技法
An Idiot’s guide to Support vector machines
Support Vector Machine(with Numerical Example)
A Tutorial on Support Vector Machines for Pattern Recognition
Machine Learning Basics
RPubs SVM